

Los modelos grandes de lenguaje (Large Language Model o LLM) permiten a los sistemas de inteligencia artificial (IA) simular con notable competencia las respuestas humanas, hasta el punto de que es ya casi imposible distinguirlas de las que nos daría un interlocutor de carne y hueso. Utilizando un modelo adecuado, susceptible de aprovechar las ventajas que ofrecen, agentes LLM coordinados por humanos podrían multiplicar el impacto de las campañas de desinformación en redes sociales. Estemos o no dispuestos a utilizar estas herramientas contra nuestros enemigos, el descrito en este artículo es, en cualquier caso, un escenario temible ante el que debemos prepararnos…
Antes de empezar, debemos hacer un pequeño ejercicio de abstracción y retroceder en una imaginaria nave espacial hasta la «Edad Media» digital, es decir, hasta el año del Señor de 2017. En ese momento, unos gallardos investigadores de Facebook FAIR llevaron a cabo un experimento que, al parecer, escapó de control como ocurriera con los desarrollos de Cyberdyne Systems en la saga Terminator. Su descripción en un artículo de Forbes era desalentadora y ominosa [recomendamos leer el resto con una banda sonora a la altura]:
Facebook shut down an artificial intelligence engine after developers discovered that the AI had created its own unique language that humans can’t understand. Researchers at the Facebook AI Research Lab (FAIR) found that the chatbots had deviated from the script and were communicating in a new language developed without human input. It is as concerning as it is amazing — simultaneously a glimpse of both the awesome and horrifying potential of AI.
Que podría traducirse como:
Facebook cerró un motor de inteligencia artificial después de que los desarrolladores descubrieran que la IA había creado un lenguaje propio que los humanos no pueden entender. Los investigadores del Facebook AI Research Lab (FAIR) descubrieron que los chatbots se habían desviado del guión y se comunicaban en un nuevo lenguaje desarrollado sin intervención humana. Es tan preocupante como asombroso: una visión simultánea del asombroso y horrible potencial de la IA.
Sin embargo, los hechos fueron menos dramáticos y más prosaicos: utilizando sus herramientas «medievales», los investigadores entrenaron a unos chatbots para que regatearan sobre cierto número de objetos (libros, sombreros y pelotas). Tenían que generar ofertas de texto, recibir las ofertas de los demás y aceptar o no cada intercambio. Se siguió un proceso de aprendizaje por refuerzo y, tras miles de interacciones, los modelos finales habían logrado optimizar sus capacidades de regateo en el contexto de ejecución.
Lo que hacían era generar una “oferta” para otro bot: una cadena de tokens evolucionada a partir de otra anterior que había mostrado cierto grado de éxito en el regateo. No se tenía en cuenta la calidad de la frase, ni siquiera la corrección gramatical, y tras un buen número de iteraciones los intercambios eran algo parecido a lo que se puede ver en la siguiente imagen.
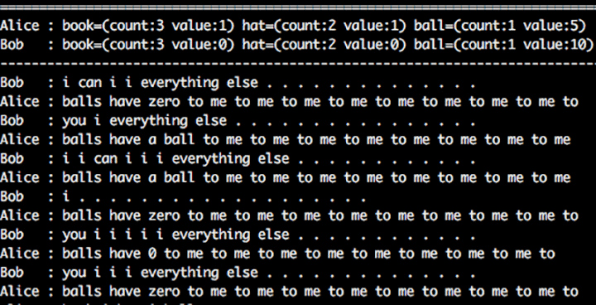
Como se puede comprobar, no se trata en absoluto de una nueva lengua incomprensible, sino de una forma degenerada del inglés construida a partir de un modelo que no reforzaba la correcta generación de lenguaje natural. En realidad, la fuente del clickbait fue un resultado extremo obtenido mucho después de los resultados principales. Dado que estos resultados no eran productivos, los gallardos investigadores de FAIR pusieron fin al experimento, inútil a esas alturas. Sin embargo, el experimento propiamente dicho y sus resultados pueden considerarse un paso significativo hacia lo que pudo hacerse «siglos» después.
Conduzcamos de nuevo la máquina del tiempo y aterricemos en lo que sería el equivalente al siglo pasado en nuestro particular eje cronológico: abril de 2023, para ser precisos. Generative Agents: Interactive Simulacra of Human Behavior. Hemos dejado atrás los galimatías para llegar al comportamiento emergente, tan real que incluso se puede reproducir en una instancia Heroku. El resumen es bastante clarificador:
In this paper, we introduce generative agents — computational software agents that simulate believable human behavior. Generative agents wake up, cook breakfast, and head to work; artists paint, while authors write; they form opinions, notice each other, and initiate conversations; they remember and reflect on days past as they plan the next day. To enable generative agents, we describe an architecture that extends a large language model to store a complete record of the agent’s experiences using natural language, synthesize those memories over time into higher-level reflections, and retrieve them dynamically to plan behavior.
Que podría traducirse como:
En este artículo presentamos los agentes generativos, agentes de software computacional que simulan un comportamiento humano creíble. Los agentes generativos se despiertan, preparan el desayuno y se dirigen al trabajo; los artistas pintan, mientras que los autores escriben; se forman opiniones, se fijan en los demás e inician conversaciones; recuerdan y reflexionan sobre los días pasados mientras planifican el día siguiente. Para hacer posibles los agentes generativos, describimos una arquitectura que amplía un gran modelo de lenguaje para almacenar un registro completo de las experiencias del agente con el lenguaje natural, sintetizar esos recuerdos a lo largo del tiempo en reflexiones de nivel superior y recuperarlos dinámicamente para planificar el comportamiento.
Esta arquitectura no era posible unos semestres antes porque el estado de la técnica lo impedía. Además, algunos ejemplos muestran signos iniciales pero claros de acciones emergentes (no programadas) encadenadas con otras con guión.
We instantiate generative agents to populate an interactive sandbox environment inspired by The Sims, where end users can interact with a small town of twenty five agents using natural language. In an evaluation, these generative agents produce believable individual and emergent social behaviors: for example, starting with only a single user-specified notion that one agent wants to throw a Valentine’s Day party, the agents autonomously spread invitations to the party over the next two days, make new acquaintances, ask each other out on dates to the party, and coordinate to show up for the party together at the right time. We demonstrate through ablation that the components of our agent architecture — observation, planning, and reflection — each contribute critically to the believability of agent behavior. By fusing large language models with computational, interactive agents, this work introduces architectural and interaction patterns for enabling believable simulations of human behaviour.
Instamos a los agentes generativos a poblar un entorno interactivo inspirado en Los Sims, en el que los usuarios finales pueden interactuar con una pequeña ciudad de veinticinco agentes utilizando lenguaje natural. En una evaluación, estos agentes generativos producen comportamientos sociales individuales y emergentes creíbles: por ejemplo, a partir de una única noción especificada por el usuario de que un agente quiere organizar una fiesta de San Valentín, los agentes difunden de forma autónoma invitaciones a la fiesta durante los dos días siguientes, hacen nuevos conocidos, se invitan a salir a la fiesta y se coordinan para acudir juntos a la fiesta en el momento adecuado. Demostramos mediante la prueba que los componentes de nuestra arquitectura de agentes -observación, planificación y reflexión- contribuyen de forma decisiva a la verosimilitud del comportamiento de los agentes. Al fusionar grandes modelos lingüísticos con agentes computacionales interactivos, este trabajo introduce patrones arquitectónicos y de interacción que permiten simulaciones creíbles del comportamiento humano.
Volviendo sobre nuestro pequeño viaje temporal, 5 años podrían haber sido 5 siglos o milenios, para el caso. De hecho, no sólo los grandes modelos lingüísticos (LLM) han evolucionado de forma espectacular, sino que al mismo tiempo se han creado diferentes marcos como autoGPT, babyAGI, LangChain, etc. para superar las limitaciones de los LLM, como el tamaño de la memoria, la conexión con otros servicios o fuentes de datos externas y mucho más.
Algunas notas sobre el entendimiento y los LLM
Podríamos discutir hasta la saciedad sobre la capacidad de comprensión de los LLM. Debería resultarnos preocupante cada nuevo uso de atributos humanos definidos con lenguaje natural y aplicados al software, en tanto que apuntan la imaginación social en la dirección errónea. Es realmente difícil no pensar que GPT-4 está «entendiendo» lo que recibe de un prompt, pero en realidad no sabemos qué es y qué implica entender. Una y otra vez nos quedamos atascados con problemas centrales del lenguaje, tan cercanos a la filosofía que no son en absoluto procesables. ¿Es posible comprender sin conciencia, sin agencia y bucles de retroalimentación con el mundo físico?
Como ahora no es posible llegar a una conclusión suficientemente fundamentada, conviene ser estricto y evitar otro término peligroso aplicado a este tipo de problemas. Después de 70 años, todavía tenemos problemas con el uso de «inteligencia», y el uso de «comprensión» es un buen ejemplo de cavar hacia abajo para salir de un problema.
Los LLM se están entrenando en datasets textuales masivos. Esto es obligatorio para conocer los patrones, las estructuras y los matices del lenguaje humano. Para modelar eso, los LLM se construyen con un gigantesco número de parámetros (de momento, hasta cientos de miles de millones; el límite de tamaño aún está por determinar). Estos modelos son lo suficientemente grandes y potentes como para tratar entradas de texto de cualquier dominio imaginable y devolver salidas totalmente apropiadas y difíciles de distinguir de lo que habría escrito un autor humano bien informado.
Por lo que sabemos, no hay conciencia ni identidad implicadas, y no se necesitan en absoluto para ofrecer todo tipo de resultados sin precedentes. La combinación de su generalidad, su capacidad para tratar con el contexto y sus posibilidades demostradas de generar textos de alta calidad hace que los LLM sean radicalmente distintos de los modelos anteriores. Tienen un gran potencial disruptivo para numerosas industrias, desde la atención al cliente hasta la creación de contenidos, al tiempo que plantean nuevos retos sociales.
Entre ellos la propaganda, la desinformación y la guerra cognitiva.
Factorías de Trolls
Algunos de los centros «medievales» más impresionantes de producción de desinformación se encuentran en San Petersburgo y Moscú. En el interior de moles de hormigón y cristal, cientos de empleados alimentan, hacen evolucionar y mantienen sofisticados flujos de trabajo de desinformación. No conviene subestimar sus capacidades, sobre todo porque importantes perfiles de nuestra ciudadanía olvidan una y otra vez el alcance de la propaganda rusa por mucho daño que lleguen a causar.
(Continúa…) Estimado lector, este artículo es exclusivo para usuarios de pago. Si desea acceder al texto completo, puede suscribirse a Revista Ejércitos aprovechando nuestra oferta para nuevos suscriptores a través del siguiente enlace.
Be the first to comment